
How to create Data Warehouse with AWS Redshift
In this project, we will create a data warehouse by using AWS and build an ETL pipeline for a database hosted on Redshift.


Introduction
A music stream startup - Sparkify has grown their user base and song database and want to move their processes and data onto the cloud. Their data resides in S3, in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app. As their data engineer, you are tasked with building an ETL pipeline that extracts their data from S3, stages them in Redshift and transforms data into a set of dimensional tables for their analytics team to continue finding insights what songs their user are listening to.

Project Structure:
create_table.py: create the fact and dimension tables for the star schema in Redshift
etl.py: load data from S3 into staging tables on Redshift and then process that data into your analytics table on Redshift
sql_queries.py: define SQL statements which will be imported into the 2 other files above.
create_cluster_redshift.py: create the AWS Redshift Cluster by using SDK
Project Step:
Step 1: Access to AWS S3 Bucket and explore datasets
Datasets used in this project are provided in two public S3 buckets
[S3]
LOG_DATA='s3://udacity-dend/log_data'
LOG_JSONPATH='s3://udacity-dend/log_json_path.json'
SONG_DATA='s3://udacity-dend/song_data'
- One bucket SONG_DATA contains info about songs and artists
- The second bucket LOG_DATA has info concerning actions done by users (which song are listening, etc.. ).
- The Redshift service is where data will be ingested and transformed, in fact though COPY command we will access to the JSON files inside the buckets and copy their content on our staging tables.
- We have two staging tables which copy the JSON file inside the S3 buckets.
How to access to AWS S3 and see what's inside ?
- Step 1: Create new IAM user on AWS account. Copy access key and secret and add to dwh.config
[CLUSTER]
HOST=dwhcluster.XXXXX.us-west-2.redshift.amazonaws.com
DB_NAME=dwh
DB_USER=dwhuser
DB_PASSWORD=dwhPassword00
DB_PORT=5439
[IAM_ROLE]
ARN=arn:aws:iam::XXXXXXXX:role/dwhRedshiftRole
[S3]
LOG_DATA='s3://udacity-dend/log_data'
LOG_JSONPATH='s3://udacity-dend/log_json_path.json'
SONG_DATA='s3://udacity-dend/song_data'
[AWS]
KEY=
SECRET=
[DWH]
DWH_CLUSTER_TYPE=multi-node
DWH_NUM_NODES=4
DWH_NODE_TYPE=dc2.large
DWH_IAM_ROLE_NAME=dwhRedshiftRole
DWH_CLUSTER_IDENTIFIER=dwhCluster
DWH_DB=dwh
DWH_DB_USER=dwhuser
DWH_DB_PASSWORD=dwhPassword00
DWH_PORT=5439
- Step 2: Load info from dwh.config and create client for EC2, IAM, Redshift:
import pandas as pd import boto3 import json config = configparser.ConfigParser() config.read_file(open('dwh.cfg')) KEY = config.get('AWS','KEY') SECRET = config.get('AWS','SECRET') DWH_CLUSTER_TYPE = config.get("DWH","DWH_CLUSTER_TYPE") DWH_NUM_NODES = config.get("DWH","DWH_NUM_NODES") DWH_NODE_TYPE = config.get("DWH","DWH_NODE_TYPE") DWH_CLUSTER_IDENTIFIER = config.get("DWH","DWH_CLUSTER_IDENTIFIER") DWH_DB = config.get("DWH","DWH_DB") DWH_DB_USER = config.get("DWH","DWH_DB_USER") DWH_DB_PASSWORD = config.get("DWH","DWH_DB_PASSWORD") DWH_PORT = config.get("DWH","DWH_PORT") DWH_PORT = config.get("DWH","DWH_PORT") DWH_PORT = config.get("DWH","DWH_PORT") DWH_ENDPOINT = config.get("DWH", "DWH_ENDPOINT") (DWH_DB_USER, DWH_DB_PASSWORD, DWH_DB) pd.DataFrame({"Param": ["DWH_CLUSTER_TYPE", "DWH_NUM_NODES", "DWH_NODE_TYPE", "DWH_CLUSTER_IDENTIFIER", "DWH_DB", "DWH_DB_USER", "DWH_DB_PASSWORD", "DWH_PORT", "DWH_IAM_ROLE_NAME"], "Value": [DWH_CLUSTER_TYPE, DWH_NUM_NODES, DWH_NODE_TYPE, DWH_CLUSTER_IDENTIFIER, DWH_DB, DWH_DB_USER, DWH_DB_PASSWORD, DWH_PORT, DWH_IAM_ROLE_NAME] }) ec2 = boto3.resource('ec2', region_name="us-east-1", aws_access_key_id=KEY, aws_secret_access_key=SECRET ) s3 = boto3.resource('s3', region_name="us-east-1", aws_access_key_id=KEY, aws_secret_access_key=SECRET ) iam = boto3.client('iam',aws_access_key_id=KEY, aws_secret_access_key=SECRET, region_name='us-east-1' ) redshift = boto3.client('redshift', region_name="us-east-1", aws_access_key_id=KEY, aws_secret_access_key=SECRET )
# Call the Bucket
bucket=s3.Bucket('udacity-dend')
song_data_files = [filename.key for filename in bucket.objects.filter(Prefix='song-data/A/A')]
song_data_files[:5]
Output:
['song-data/A/A/A/TRAAAAK128F9318786.json',
'song-data/A/A/A/TRAAAAV128F421A322.json',
'song-data/A/A/A/TRAAABD128F429CF47.json',
'song-data/A/A/A/TRAAACN128F9355673.json',
'song-data/A/A/A/TRAAAEA128F935A30D.json']
Song Datasets
s3.Bucket('udacity-dend').download_file(song_data_files[0], 'song_data_file_tst.json')
with open('song_data_file_tst.json') as json_file:
data = json.load(json_file)
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(data)
Output:
{ 'artist_id': 'ARJNIUY12298900C91',
'artist_latitude': None,
'artist_location': '',
'artist_longitude': None,
'artist_name': 'Adelitas Way',
'duration': 213.9424,
'num_songs': 1,
'song_id': 'SOBLFFE12AF72AA5BA',
'title': 'Scream',
'year': 2009}
Log Datasets
log_data_files = [filename.key for filename in bucket.objects.filter(Prefix='log-data')]
log_data_files[:5]
Output:
['log-data/',
'log-data/2018/11/2018-11-01-events.json',
'log-data/2018/11/2018-11-02-events.json',
'log-data/2018/11/2018-11-03-events.json',
'log-data/2018/11/2018-11-04-events.json']
s3.Bucket('udacity-dend').download_file('log-data/2018/11/2018-11-04-events.json', 'log_data_file_tst.txt')
num_list = []
with open('log_data_file_tst.txt', 'r') as fh:
for line in fh:
num_list.append(line)
data = json.loads(num_list[0])
pp.pprint(data)
Output:
{ 'artist': None,
'auth': 'Logged In',
'firstName': 'Theodore',
'gender': 'M',
'itemInSession': 0,
'lastName': 'Smith',
'length': None,
'level': 'free',
'location': 'Houston-The Woodlands-Sugar Land, TX',
'method': 'GET',
'page': 'Home',
'registration': 1540306145796.0,
'sessionId': 154,
'song': None,
'status': 200,
'ts': 1541290555796,
'userAgent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 '
'Firefox/31.0',
'userId': '52'}
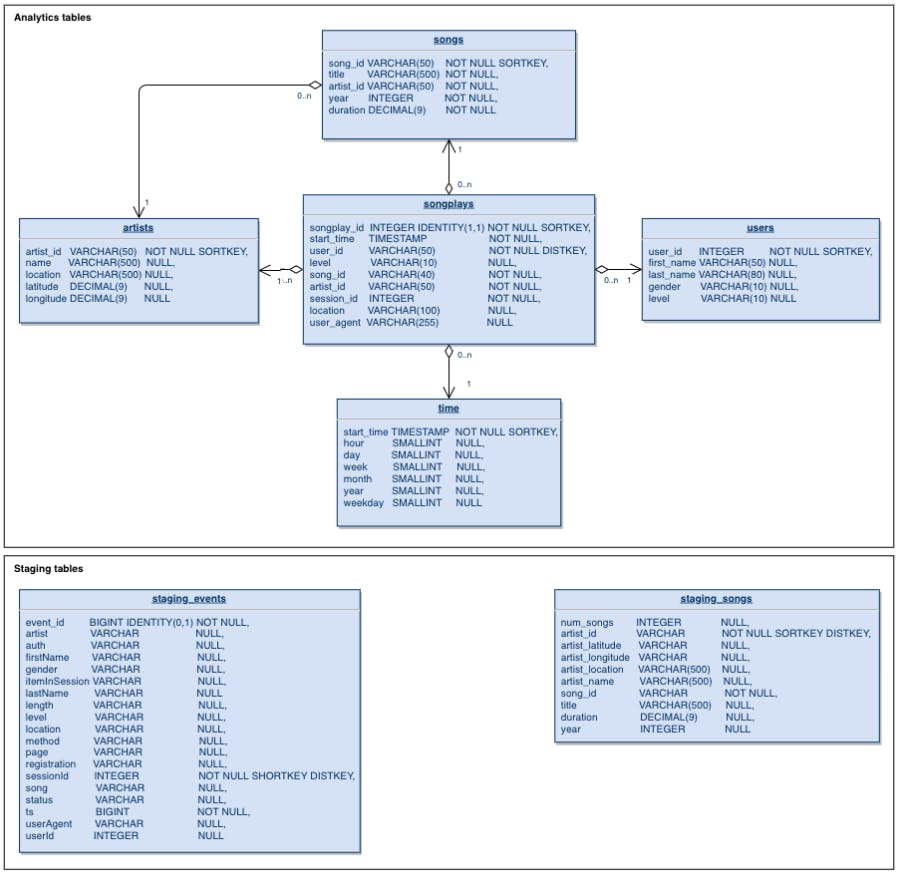
Step 2: Create table schemas
Instead of reading data directly from the s3 buckets into the final database, this project will make use of a staging table to act as an intermediary between the s3 bucket and the final database
There are two staging tables staging_events and the staging_songs tables. These tables are to temporally hold data from the S2 Bucket before being transformed and inserted into the primary use tables. Here is final SQL Statement
Step 3: Creating Redshift Cluster using the AWS python SDK
- Step 1: Create an IAM Role that makes Redshift able to access S3 bucket (ReadOnly)
# TODO: Create the IAM role
try:
print('1.1 Creating a new IAM Role')
dwhRole = iam.create_role(
Path='/',
RoleName=DWH_IAM_ROLE_NAME,
Description='Allows Redshift clusters to call AWS services on your behalf.',
AssumeRolePolicyDocument=json.dumps({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}),
)
except Exception as e:
print(e)
Creating a new IAM Role
# TODO: Attach Policy
print('1.2 Attaching Policy')
iam.attach_role_policy(RoleName=DWH_IAM_ROLE_NAME,
PolicyArn="arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess"
)['ResponseMetadata']['HTTPStatusCode']
Attaching Policy
# TODO: Get and print the IAM role ARN
print('1.3 Get the IAM role ARN')
roleArn = iam.get_role(RoleName=DWH_IAM_ROLE_NAME)['Role']['Arn']
print(roleArn)
Step 2: Create Redshift Cluster
try: response = redshift.create_cluster( #HW ClusterType=DWH_CLUSTER_TYPE, NodeType=DWH_NODE_TYPE, NumberOfNodes=int(DWH_NUM_NODES), #Identifiers & Credentials DBName=DWH_DB, ClusterIdentifier=DWH_CLUSTER_IDENTIFIER, MasterUsername=DWH_DB_USER, MasterUserPassword=DWH_DB_PASSWORD, #Roles (for s3 access) IamRoles=[roleArn] ) except Exception as e: print(e)Step 3: Open an incoming TCP port to access the cluster ednpoint
try: vpc = ec2.Vpc(id=myClusterProps['VpcId']) defaultSg = list(vpc.security_groups.all())[0] print(defaultSg) defaultSg.authorize_ingress( GroupName=defaultSg.group_name, CidrIp='0.0.0.0/0', IpProtocol='TCP', FromPort=int(DWH_PORT), ToPort=int(DWH_PORT) ) except Exception as e: print(e)
Step 4: Connect to DB and create table
import configparser
import psycopg2
from sql_queries import create_table_queries, drop_table_queries
def drop_tables(cur, conn):
"""
Delete pre-existing tables to be able to create them from scratch
"""
print('Droping tables')
for query in drop_table_queries:
cur.execute(query)
conn.commit()
def create_tables(cur, conn):
"""
Create staging and dimensional tables declared on sql_queries script
"""
for query in create_table_queries:
cur.execute(query)
conn.commit()
def main():
"""
Set up the database tables, create needed tables with the appropriate columns and constricts
"""
config = configparser.ConfigParser()
config.read('dwh.cfg')
conn = psycopg2.connect("host={} dbname={} user={} password={} port={}".format(*config['CLUSTER'].values()))
cur = conn.cursor()
print('Connected to the cluster')
drop_tables(cur, conn)
create_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
Step 5: Build ETL Pipeline
import configparser
import psycopg2
from sql_queries import copy_table_queries, insert_table_queries
def load_staging_tables(cur, conn):
#Load data from files stored in S3 to the staging tables using the queries declared on the sql_queries script
for query in copy_table_queries:
cur.execute(query)
conn.commit()
def insert_tables(cur, conn):
#Select and Transform data from staging tables into the dimensional tables using the queries declared on the sql_queries script
for query in insert_table_queries:
cur.execute(query)
conn.commit()
def main():
#Extract songs metadata and user activity data from S3, transform it using a staging table, and load it into dimensional tables for analysis
config = configparser.ConfigParser()
config.read('dwh.cfg')
conn = psycopg2.connect("host={} dbname={} user={} password={} port={}".format(*config['CLUSTER'].values()))
cur = conn.cursor()
load_staging_tables(cur, conn)
insert_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
Step 6: Clean up your resources
redshift.delete_cluster( ClusterIdentifier=DWH_CLUSTER_IDENTIFIER, SkipFinalClusterSnapshot=True)
myClusterProps = redshift.describe_clusters(ClusterIdentifier=DWH_CLUSTER_IDENTIFIER)['Clusters'][0]
prettyRedshiftProps(myClusterProps)
iam.detach_role_policy(RoleName=DWH_IAM_ROLE_NAME, PolicyArn="arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess")
iam.delete_role(RoleName=DWH_IAM_ROLE_NAME)