
ETL with PostgreSQL
In this project, you'll apply what you've learned on data modeling with Postgres and build an ETL pipeline using Python


Introduction
A startup called Sparkify wants to analyze the data they've been collecting on songs and user activity on their new music streaming app. They'd like a data engineer to create a Postgres database with tables designed to optimize queries on song play analysis, and bring you on the project. Your role is to create a database schema and ETL pipeline for this analysis. So the first we need to do is analyze the data, let's see what inside
Song Dataset
Songs dataset is a subset of Million Song Dataset.
Sample record:
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
Log Dataset
Logs dataset is generated by Event Simulator.
Sample Record:
{"artist": null, "auth": "Logged In", "firstName": "Walter", "gender": "M", "itemInSession": 0, "lastName": "Frye", "length": null, "level": "free", "location": "San Francisco-Oakland-Hayward, CA", "method": "GET","page": "Home", "registration": 1540919166796.0, "sessionId": 38, "song": null, "status": 200, "ts": 1541105830796, "userAgent": "\"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10_9_4) AppleWebKit\/537.36 (KHTML, like Gecko) Chrome\/36.0.1985.143 Safari\/537.36\"", "userId": "39"}
Design Schema
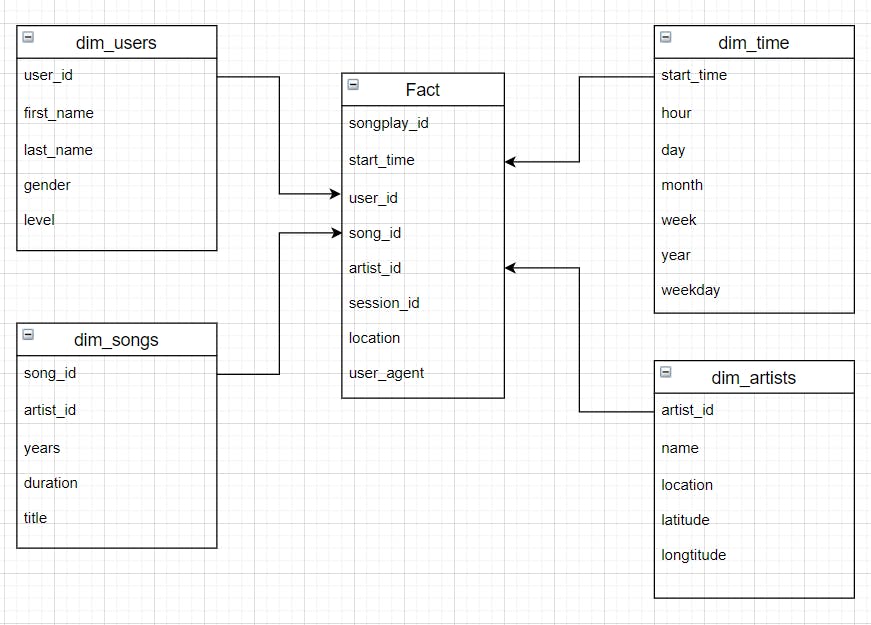
Project Files
sql_queries.py -> contains sql queries for dropping and creating fact and dimension tables. Also, contains insertion query template.
create_tables.py -> contains code for setting up database. Running this file creates sparkifydb and also creates the fact and dimension tables.
etl.py -> read and process song_data and log_data
test.ipynb -> a notebook to connect to postgres db and validate the data loaded.
Project Steps
Create Tables
- Write CREATE statements in sql_queries.py to create each table.
# CREATE TABLES songplay_table_create = ("""CREATE TABLE IF NOT EXISTS songplays( songplay_id SERIAL CONSTRAINT songplay_pk PRIMARY KEY, start_time TIMESTAMP REFERENCES time (start_time), user_id INT REFERENCES users (user_id), level VARCHAR NOT NULL, song_id VARCHAR REFERENCES songs (song_id), artist_id VARCHAR REFERENCES artists (artist_id), session_id INT NOT NULL, location VARCHAR, user_agent TEXT )""")user_table_create = ("""CREATE TABLE IF NOT EXISTS users( user_id INT CONSTRAINT users_pk PRIMARY KEY, first_name VARCHAR, last_name VARCHAR, gender CHAR(1), level VARCHAR NOT NULL )""")song_table_create = ("""CREATE TABLE IF NOT EXISTS songs( song_id VARCHAR CONSTRAINT songs_pk PRIMARY KEY, title VARCHAR, artist_id VARCHAR REFERENCES artists (artist_id), year INT CHECK (year >= 0), duration FLOAT )""")artist_table_create = ("""CREATE TABLE IF NOT EXISTS artists( artist_id VARCHAR CONSTRAINT artist_pk PRIMARY KEY, name VARCHAR, location VARCHAR, latitude DECIMAL(9,6), longitude DECIMAL(9,6) )""")time_table_create = ("""CREATE TABLE IF NOT EXISTS time( start_time TIMESTAMP CONSTRAINT time_pk PRIMARY KEY, hour INT NOT NULL CHECK (hour >= 0), day INT NOT NULL CHECK (day >= 0), week INT NOT NULL CHECK (week >= 0), month INT NOT NULL CHECK (month >= 0), year INT NOT NULL CHECK (year >= 0), weekday VARCHAR NOT NULL )""") Write DROP statements in sql_queries.py to drop each table if it exists
# DROP TABLES songplay_table_drop = "DROP TABLE IF EXISTS songplays" user_table_drop = "DROP TABLE IF EXISTS users" song_table_drop = "DROP TABLE IF EXISTS songs" artist_table_drop = "DROP TABLE IF EXISTS artists" time_table_drop = "DROP TABLE IF EXISTS time"Run create_tables.py to create your database and tables.
import psycopg2 from sql_queries import create_table_queries, drop_table_queries def create_database(): #connect to defaut database conn = psycopg2.connect("host=localhost dbname=studentdb user=postgres password=mysecretpassword") conn.set_session(autocommit=True) cur = conn.cursor() # create sparkify database with UTF8 encoding cur.execute("DROP DATABASE IF EXISTS sparkifydb") cur.execute("CREATE DATABASE sparkifydb WITH ENCODING 'utf8' TEMPLATE template0") #close connection to default database conn.close() conn = psycopg2.connect("host=localhost dbname=sparkifydb user=postgres password=mysecretpassword") cur = conn.cursor() return cur, conn def drop_table(cur,conn): for query in drop_table_queries: cur.execute(query) conn.commit() def create_table(cur,conn): for query in create_table_queries: cur.execute(query) conn.commit() def main(): cur, conn = create_database() drop_table(cur, conn) print("Table dropped sucessfully!!") create_table(cur,conn) print("Table created successfully!!") conn.close() if __name__ == '__main__': main()- Run in terminal
python create_tables.py Run test.ipynb to confirm the creation of your tables with the correct columns. Make sure to click "Restart kernel" to close the connection to the database after running this notebook.
Once verified that base steps were correct by checking with test.ipynb, filled in etl.py program.
import os import glob import psycopg2 import pandas as pd from sql_queries import * def process_song_file(cur, filepath): """ Process songs files and insert records into the Postgres database. :param cur: cursor reference :param filepath: complete file path for the file to load """ # open song file df = pd.DataFrame([pd.read_json(filepath, typ='series', convert_dates=False)]) for value in df.values: num_songs, artist_id, artist_latitude, artist_longitude, artist_location, artist_name, song_id, title, duration, year = value # insert artist record artist_data = (artist_id, artist_name, artist_location, artist_latitude, artist_longitude) cur.execute(artist_table_insert, artist_data) # insert song record song_data = (song_id, title, artist_id, year, duration) cur.execute(song_table_insert, song_data) print(f"Records inserted for file {filepath}") def process_log_file(cur, filepath): """ Process Event log files and insert records into the Postgres database. :param cur: cursor reference :param filepath: complete file path for the file to load """ # open log file df = df = pd.read_json(filepath, lines=True) # filter by NextSong action df = df[df['page'] == "NextSong"].astype({'ts': 'datetime64[ms]'}) # convert timestamp column to datetime t = pd.Series(df['ts'], index=df.index) # insert time data records column_labels = ["timestamp", "hour", "day", "weelofyear", "month", "year", "weekday"] time_data = [] for data in t: time_data.append([data ,data.hour, data.day, data.weekofyear, data.month, data.year, data.day_name()]) time_df = pd.DataFrame.from_records(data = time_data, columns = column_labels) for i, row in time_df.iterrows(): cur.execute(time_table_insert, list(row)) # load user table user_df = df[['userId','firstName','lastName','gender','level']] # insert user records for i, row in user_df.iterrows(): cur.execute(user_table_insert, row) # insert songplay records for index, row in df.iterrows(): # get songid and artistid from song and artist tables cur.execute(song_select, (row.song, row.artist, row.length)) results = cur.fetchone() if results: songid, artistid = results else: songid, artistid = None, None # insert songplay record songplay_data = ( row.ts, row.userId, row.level, songid, artistid, row.sessionId, row.location, row.userAgent) cur.execute(songplay_table_insert, songplay_data) def process_data(cur, conn, filepath, func): """ Driver function to load data from songs and event log files into Postgres database. :param cur: a database cursor reference :param conn: database connection reference :param filepath: parent directory where the files exists :param func: function to call """ # get all files matching extension from directory all_files = [] for root, dirs, files in os.walk(filepath): files = glob.glob(os.path.join(root,'*.json')) for f in files : all_files.append(os.path.abspath(f)) # get total number of files found num_files = len(all_files) print('{} files found in {}'.format(num_files, filepath)) # iterate over files and process for i, datafile in enumerate(all_files, 1): func(cur, datafile) conn.commit() print('{}/{} files processed.'.format(i, num_files)) def main(): """ Driver function for loading songs and log data into Postgres database """ conn = psycopg2.connect("host=localhost dbname=sparkifydb user=postgres password=mysecretpassword") cur = conn.cursor() process_data(cur, conn, filepath='data/song_data', func=process_song_file) process_data(cur, conn, filepath='data/log_data', func=process_log_file) conn.close() if __name__ == "__main__": main() print("\n\nFinished processing!!!\n\n")- Run etl in terminal, and verify results:
python etl.py
Build ETL Pipeline
Prerequisites: Database and tables created
On the etl.py we start our program by connecting to the sparkify database, and begin by processing all songs related data.
We walk through the tree files under /data/song_data, and for each json file encountered we send the file to a function called process_song_file.
Here we load the file as a dataframe using a pandas function called read_json().
For each row in the dataframe we select the fields we are interested in:
song_data = [song_id, title, artist_id, year, duration]artist_data = [artist_id, artist_name, artist_location, artist_longitude, artist_latitude]Finally, we insert this data into their respective databases.
Once all files from song_data are read and processed, we move on processing log_data.
We load our data as a dataframe same way as with songs data.
Source Code : github.com/flynn3103/Data_Engineer_Project/..